




Table of contents
Linear regression is a supervised Machine Learning algorithm used for regression, which is a technique employed to predict continuous outcomes, that consists of fitting a line. It is easily interpretable thanks to its simplicity. Below is a graphical representation of Linear Regression for a single independent variable:
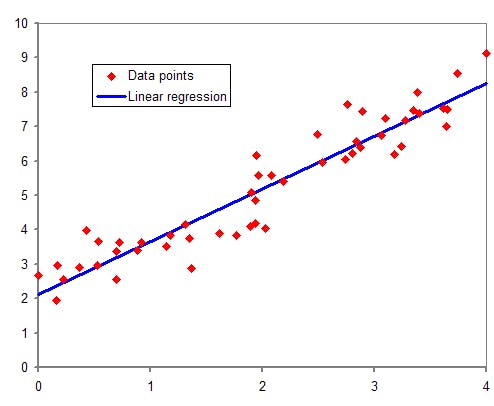
There are two types:
- Simple linear regression: this is the simplest case, there is only one independent variable. The model is described with the following equation:
$$ y = B_0 + B_1 x_1 $$
- Multiple linear regression: there is more than one independent variable. This is the general case, which describes the model as follows: $$ y = B_0 + B_1 x_1 + ... + B_n x_n $$
Model training
The way the model is trained is by estimating the value of the B coefficients that best adjust to the available data.
To achieve that, the following cost function has to be minimised, which in Linear Regression corresponds to the sum of the squared residuals (difference between actual values y and predictions ŷ):
$$\mathrm{J} = \dfrac{1}{n}\sum_{n=1}^{n} (y_i-\hat y_i)^2$$
The residuals are described as the difference between the actual values and the predicted ones. A visual example is shown below:
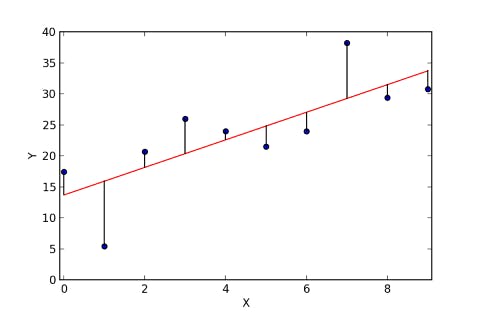
There are different approaches to minimise this function:
Ordinary Least Squares
This approach deals with data in the matrix form and calculates the optimal values for the coefficients using linear algebra operations.
On the one hand, the optimal values can be found and it is a very fast method. On the other hand, it uses all available data, meaning that there must be enough memory to fit it all and perform the algebra operations.
This is the approach used by Scikit-Learn’s library LinearRegression.
Gradient Descent
This approach consists of iteratively calculating the direction of the error and updating the value of the coefficients accordingly to minimise the cost function.
This approach is recommended when the data size is too large to fit in memory.
This approach can be used with Scikit-Learn’s library SGDRegressor.
Data preparation
For the Linear Regression model to work properly, the input data must be suitable for the model. Following, are some considerations when preparing the data. Some of them are also common to other Machine Learning models:
- Input data must be numeric as Linear Regression models do not accept categorical features.
- Input data must be scaled or standardised so all of them range within a similar interval. This will prevent the model to set a greater weight for features with a larger range.
- Outliers must be removed to prevent model disturbances in the training.
- Missing values must be either removed or handled.
- Remove features that are highly correlated with other features to prevent collinearity.
- Handle features that are not linearly correlated with the target variable.
- Remove those variables that do not add any information, in order not to introduce noise.
- To increase the reliability of the model, it must be ensured that the features follow a Gaussian or normal distribution. Otherwise, some transformations like the logarithm may be required.
If you liked this content don't forget to follow me here and on Twitter!
